So this Hash Match at 31% is the highest one. The next closest is a 14% and 10% both clustered indexes. What can I do with this information?
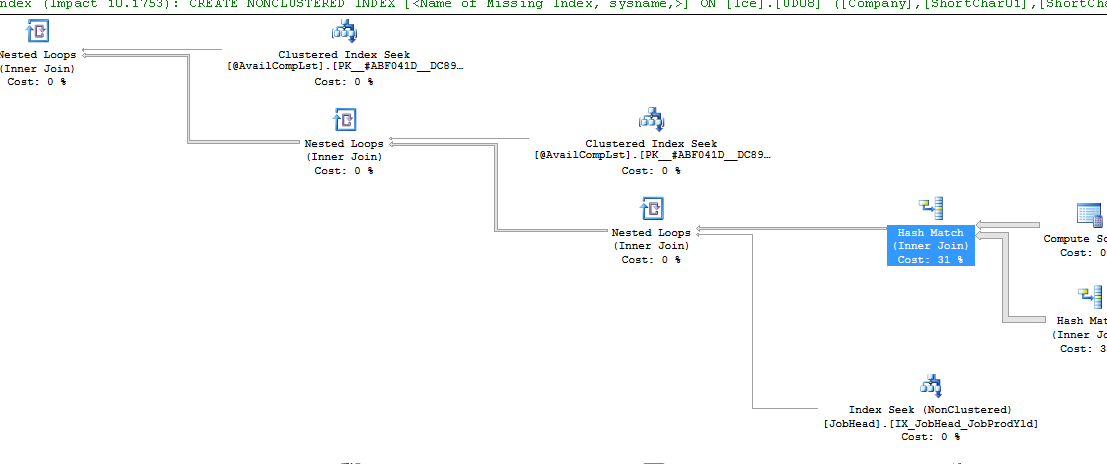
The green text at the top of your screenshot is the recommendation. There is probably the option to create the missing index using a script that it’s already prepared for you.
1 Like
How do I add an index to a BAQ?
You don’t, you add the index to the table/ db
So I would have to keep updating that index then as data is added? What if the data for that index changes, (see the part number change example above).
Well the index once added to your DB will be maintained like all other indexes in the DB. you shouldn’t have to do much (other than run the maintenance jobs)
So basically what this is saying to do? Create the index. How does E-10 know to use it then? Does this new column show up in the BAQ editor? Or do I have to make this an external query to make it work? Sorry about the dumb questions, remember I’m a manufacturing engineer, not an IT guy/software developer…
1 Like
So an index is just (like in a book) it tells the DB where to find certain records. You run the create index command in the Epicor DB and it generates the index. From then on any time you run a query which makes use of this index (IE, it uses all the keys indexed by the index) it will use it to find the records faster.
So just to make sure I understand (in terms of my example), I would create the index on the columns ShortChar01 (part number) and ShortChar03(parent part number). Then when I am trying to join using those 2 columns, E10 will look at the index say “hey we have an index for those” and use that instead of the table scan, right?
Once the index script is run, it will create the index for existing records, then when new ones are added are the indexes added with new rows, Right? Then the maintenance job that you are talking about should reorganize the indexes after they have been added on a periodic basis to make it most efficient. Is that description accurate?
This article explains some general ideas about indexes and SQL maintenance. These ideas apply to what I am talking about right?
Correct.
The stuff in green in the execution plan is the “script” you need to run to create those indexes. (just give it a better name than
One thing to keep in mind don’t start creating indexes left and right for all your BAQs, only for things that are truly causing pain should you venture into index creation land.
Oh yeah and always try it in TEST first. By the way those “maintenance” jobs I spoke about aren’t magically there by default, your IT staff should already be running maintenance on your e10 DB (re-index, re-builds, stats updates, backups etc…) just throwing that out-there in case
So I added the index to the pilot database. Putting the same query in the same dashboard, running the same filter, (job number) and Production runs faster than pilot. Production should have more data than pilot, since pilot is older.
The index that I added is ShortChar01 (PartNum) and ShortChar03 (ParentPartNum). ShortChar02 is my pack status, and it’s what I need to look up the history for. I’m only joining by 01 and 03. The recommendation called for 02 as well. Not knowing how the indexing works I figured I would only want the joins to be in the index, so I only added 01 and 03. Should I add 02 as well? (I’m going to try it anyways, I’m just trying to learn about the theory of how indexing works)
So the index only works with the keys you gave it, adding 02 should not be necessary.
So I tried it out and without 02 in there, it takes a long time or times out. With 02 in there, it finishes in about 4 seconds. So I have the index order ShortChar03 (parent), ShortChar02(part), ShortChar02. I think this will be what I need to make it work well.
Funny thing is, I haven’t added any index to production, but production runs very quickly. Does SQL look at usage (like me constantly testing) and see that and make some adjustments?
The other theory that I have is that production would have fewer empty strings in ShortChar02, as they have been set in production since we copied over to Pilot. Could this have an impact on performance?
Could it potentially hurt performance?
1 Like
SQL does look at usage (via stats updated)
Not i should not hurt performance.
In case anyone is wondering, these are the things that I did to improve performance on this BAQ.
I added the JobHead table to my sub-queries that had any epicor tables in it. I didn’t use any of the fields, but it seems to have helped. That was per suggestion by @knash during our webex.
Per @danbedwards suggestion, I set a criteria for every table to set to my company. I did not use the BAQ constant to do this, that made performance worse, I set = constant and typed my company name criteria.
I created an index with Company, ShortChar03, ShortChar01, and ShortChar02. In that orders. This was per the recommendation of the SQL plan.
Doing those 3 things make the query run much faster. I’m still trying to learn how to know what things to do in these situations.
Hopefully my live roll out of this duplicates what I am seeing in the Pilot system.
2 Likes
You might have been able to get this to work with the index on the ud table. I am guessing what we did just leveraged a different index. The plan will tell you more. Have you checked out the execution plan in toad?
That’s what I did. I added the index on UD08
I tried, but since toad doesn’t like the calculated fields, it wouldn’t give me a plan with the SQL copy and pasted. I tried to adjust the SQL but don’t know enough to be able to get it to work. I also tried to open the plan from Epicor in Toad, but it doesn’t know how to read that either. I just looked at the plan in MSSQL server.
I meant if we just started with adding the index on the UD table first, when added the JobHead table. Wonder what the query would do now without the added table connection.
2 Likes
Well, let me try it…
Yup, @knash is right. I Copied the query, and remove JobHead tables from everything, runs about the same as the one with them. If the execution times are believable for a limited query, the one without the job head runs slightly faster. (4348 ms without vs 4625 ms with.)
Nice a 6% improvement!!!
We are making you into an IT stud!!!
1 Like