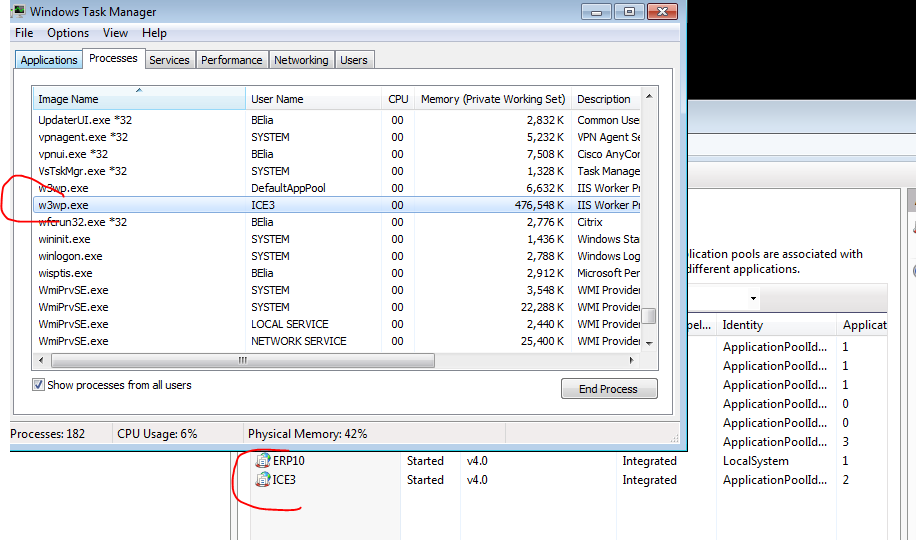
Does anyone know, where on the server Epicor or IIS is saving cache? Sometime I have a BO method that all of a sudden decides to take forever to finish. The only way I can ever get it back to normal is to restart the server. There has to be somewhere I can clear a cache folder on the server then recycle IIS to achieve the same thing?
I already tried deleting the files in C:\Windows\Microsoft.NET\Framework64\v4.0.30319\Temporary ASP.NET Files but that did not make the BO method work as expected.
That’s a lot of data (potentially)… how many lines on these invoices. We’ve had this issue in the past there is some legacy code that runs an “AfterRow” event for each Invoice / Invoice Line / InvoiceDtl and running a SQL profile shows basically N^N queries running for each record… It’s kind of insane.
In one instance we had to limit (via BPM) the number of records we allowed on a single invoice batch to get past it.
However restarting the Server didn’t fix it for us…
I have a test database with 988 invoices for the same customer and it takes less than 5 seconds. I understand that no one is logged in to this test environment but me, but the difference should not be so drastic. I know when I restart the server I will see a similar time to retrieve the same amount of records. This is happening when clicking a retrieve button by the way.
This all assumes a ‘normal’ configuration of IIS - I won’t go into the history of IIS In Process, Out Of Process and my favorite acronym of all time - Pooled Out Of Process mode - all sanitized by marketing since IIS 3 days.
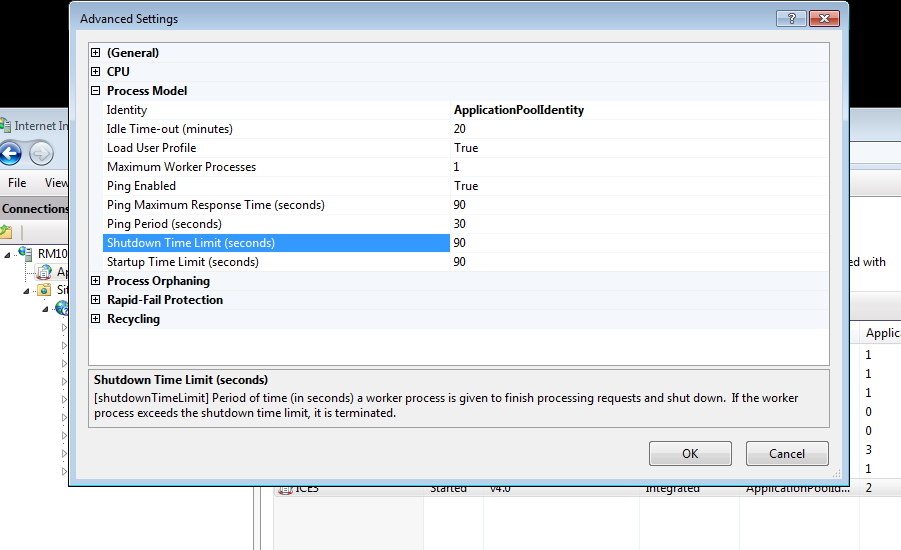
What you may be seeing is the normal delay in how recycling of app pools are processed. When you recycle an App Pool or it crashes, a new w3wp is stood up immediately. When you recycle it though it does not kill off existing processes immediately. There is a timeout on the shut down of the old w3wp to let it finish working upon any existing work - all new work goes to the new w3wp but the old work is allowed to finish for a certain length of time as shown in the advanced settings for app pools:
They probably did not wait for the shutdown time. You should control the shutdown based on different factors. If running an mrp or big report overnight, you probably don’t want to redo that work so a long shutdown is desired. If fighting a runaway process, a shorter one is wanted while you track down why you need to keep recycling the app pool (Or the app pool recycles on it’s own based upon your settings)
Safe Harbor
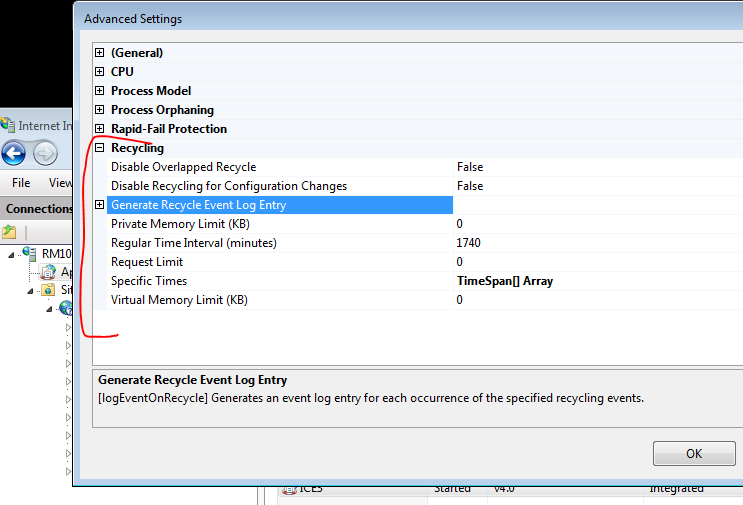
I personally like to recycle app pools regularly in many apps. As long as your shutdown timer is long enough, no work is ‘lost’. You constantly get fresh processes so no overhead from a memory leak or caches not being freed as fast as I want when I am wearing my IT Admin hat. Having this tool in your toolbelt to make folks happy while tracking something down is valuable for all of us trying to balance everything.
ERP 10 HEAVILY caches as everyone watching a recycled server crawl awake notices. So there is that to factor into how you like to admin your boxes. I have heard some customers recycling their boxes on the weekends or at night and having some scripts like Curl commands executing from a task scheduler a little after the app pool recycle or the like - something to warm up and cache the server values of interest so users Monday morning are not irritated.
In an ideal world, no need for any of this would occur. In the real world however, hopefully knowing how this ties together will keep you sane while tracking down issues in that BPM, etc
Thank you @Bart_Elia for the great insight to IIS, really informative post. I’m going to turn on more tracing and try to find out what is causing this to be so slow.
if any one interested, after having several issue that required IIS App pool to be recycled on regular bases, i end up writing a PowerShell script attached to Task Schedule Manager to do that on off work time, then write a customised log event only if error out.